SDBMS 공간데이터베이스
③ SAM, The Grid File
0. SAM
The main purpose of spatial access methods is
to support efficient selection of objects based on spatial properties. *
SAM = 공간적 특성이 있는 객체를 좀 효율적으로 고르는 방법. 이라고 이해하면 된다.
점, 선, 면을 object자체보다 단순화해서
MBR(Minimum Bounding Rectangle)이나 MBB(Minimum Bounding Box)로 나타내는 방법을 사용하면
복잡한 도형도 간단히 표시할 수 있고, 일정한 크기의 entry로 사용할 수 있다는 장점이 있다.
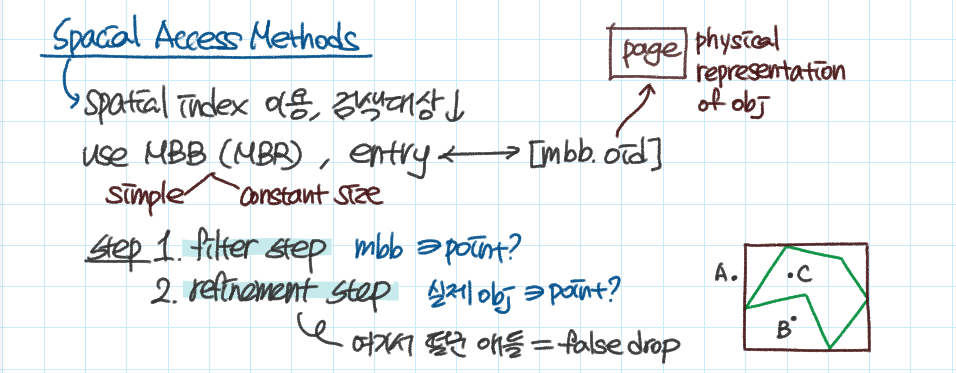
즉 각 entry의 자세한 정보는 page에 저장하고
page로 접근 가능한 주소(oid)와 entry를 간단히 나타낸 사각형(mbb)로 표현할 수 있다.
MBB를 이용한 검색은 두 단계로 나눠서 구할 수 있다.
1단계. filter step, 우선 탐색할 대상을 줄이는 단계
2단계. refinement step, 정확한 결과를 얻어내는 단계
위 그림의 초록색 다각형 내부에 존재하는 점을 검색할 때, 갈색 사각형이 해당 다각형의 MBR이 되며
1단계에서 A 거르고
2단계에서야 B를 거르고 C를 얻어낼 수 있다.
이때 B처럼 refinement step에서 걸러진 것들을 false drop이라고 한다.

공간데이터의 indexing에서 B+tree를 쓰기엔 부적절하다.
B+tree는 total order을 지원하지만
일반적으로 공간 상에서 total order는 성립하지 않아 공간데이터와는 어울리지 않기 때문
공간데이터 인덱싱에선 주로 두 가지 구조를 사용한다.
1. Space Driven Structure
- 공간을 분할하고, 각 공간에 mapping되는 객체를 인덱싱
- The Grid File, The Linear Quad Tree, The z-Ordering Tree, KD Tree ...
2. Data Driven Structure
- 객체들을 위치에 따라 적절하게 묶어 인덱싱
- R tree, R*tree, R+tree, M tree ....
공간을 기준으로 했느냐, 객체 자체를 기준으로 했느냐의 차이.
①에서 Spatial model을 filed based로 했는지 object based로 했는지와 비슷한 맥락으로 보면 되겠다.
1. The Grid File

공간을 동일한 크기의 cell로 나누어 관리하는 구조
각 cell에 대응되는 directory에는 disk page의 주소를 저장, 한 개 이상의 page와 mapping한다.
page에는 당연히 해당 cell에 존재하는 객체의 정보가 저장될 것
원점, 공간 전체의 크기, cell의 개수, x축 및 y축의 directory index(?) 등이 필요하다.

여기서는 원점이 (x0,y0)
전체 공간 Sx×Sy에서 Sx=x4-x0, Sy-y4-y0
cell 개수는 nx=4, ny=4 총 16개이다.
DIR[1:4,1:4]의 2차원 배열을 이용해 인덱싱한다.
왼쪽 좌표의 1번 셀의 디렉토리는 DIR[2,3], 2번 셀의 디렉토리는 DIR[4,3]으로 나타낸다.
하나의 disk page capacity가 점 4개, cell capacity는 8개라고 하면
1번 셀의 경우 한 page만 있어도 되지만
2번 셀의 경우 [o]를 저장하는 overflow page를 가진다.
즉 page overflow가 날 경우 linked list처럼 페이지를 연결한다.
2. Insert & Split
Grid File에 데이터를 삽입할 때는 위의 (x0,y0),Sx,Sy,nx,ny 등을 이용해 index를 구하여 page에 접근한다.
셀은 데이터의 개수가 늘어나면 분할된다. 셀에 대응하는 page도 당연히 분할된다.
앞의 그림에서 점이 계속해서 입력되면 각 셀을 x축에 평행하게 이등분해 DIR[1:4,1:8]로 인덱싱을 할 수도 있다.
즉 cell split이나 directory split이 일어난다.

다시보니 split이 엄청 헷갈리는 것 같은데
overflow page는 cell capacity가 page capacity보다 커서, 한 cell이 여러 개의 page와 mapping될 때 생기는 것
cell split은 엄밀히는 page split이라고 보면 되겠다.
Split은 세 가지 경우에서 발생한다.
No Cell Split: directory는 분할되지만 실제로 page 분할 X
Cell Split & No Directory Split: directory의 변화는 없고 page만 분할
Cell Split & Directory Split: directory와 page모두 분할
일단 point data를 저장할 때를 예로 들어보자. cell capacity=4 page capacity=4 (점 개수)로 가정

A 전체 공간에 점이 4개만 존재. DIR[1,1]
B 점 세 개 추가, 셀에 overflow 발생, cell을 이등분함. DIR[1:2,1]
다섯 번째 점을 삽입할 때 부터, 셀과 디렉토리의 overflow가 발생해 둘 다 분할. Cell & Dir Split
왼쪽 셀 ----- DIR[1,1] --- page p1
오른쪽 셀 --- DIR[2,1] --- page p2
C 점이 한 개 추가됨. B의 왼쪽 셀에 overflow 발생, cell을 이등분함. DIR[1:2,1:2]
이 때 두 가지 split이 발생한다.
Cell & Dir Split: page p1이 p1과 p3으로 분할, DIR[1,1]이 DIR[1,1]과 DIR[1,2]로 분할
No Cell Split: DIR[2,1]이 DIR[2,1]과 DIR[2,2]로 분할되지만 두 디렉토리 모두 p2로 mapping
D 점이 추가되었지만 셀의 크기는 유지한다. DIR[1:2,1:2]
이때 DIR[2,1]와 DIR[2,2]는 그대로지만 각각 mapping되는 page가 p4와 p2로 분할
이런 상황이 Cell & No Dir Split
아래는 객체가 사각형이거나 MBR을 인덱싱하는 경우

그런데 여기서 의문점이,, 동일한 크기의 cell을 이용한다면서 여기서 그림은 왜 이 상태인지..?
갑자기 무슨 일이 일어났던 건지,,,?
* Discussion
위 그림에서 8번 객체는 셀 두 개에 걸쳐있어 중복저장된다. 즉 grid file은
- 셀의 크기가 작을수록 중복저장의 빈도가 높다.
- 디렉토리가 메모리에 존재할 경우 효율성이 안 좋다. 즉 큰 데이터에는 어울리지 않는다.
3. Query
Space-Driven Structure에서 주로 본 쿼리는 Point query와 Window Query이다.
Point Query: 주어진 점을 포함한 객체 검색
Window Query: 주어진 사각형 범위와 겹치는 객체 검색
둘 다 비슷한 방식으로 동작한다.
인덱스를 구해서 검색할 페이지를 추리고
해당 페이지 내의 객체를 검사해 원하는 결과를 얻으면 된다.
때에 따라 중복 제거나 정렬을 하기도 함
1. Point Query, P(a,b)
begin
result = {}
//Compute the cell containing P
i=Rank(a,Sx), j=Rank(b,Sy) // Calculate index
page=ReadPage(DIR[i,j].PageID) // Get page
for each e in page do // Check each object of page
if (P is in e.mbb) then result+=(e.oid)
end for
return result
end
2. Window Query, W(x1,y1,x2,y2)
begin
result = {}
// Compute the cells
i1=Rank(x1,Sx), j1=Rank(y1,Sy) // Calculate index
i2=Rank(x2,Sy), j2=Rank(y2,Sy)
for each i in [i1:i2] do
for each j in [j1:j2] do
page=ReadPage(DIR[i,j].PageID) // Get Page
for each e in page do // Check each object in page
if(W INTERSECT e.mbb) then result+=(e.oid)
end for
end for
end for
// Sort and Remove duplication
Sort(result)
RemoveDupl(result)
return result
end
Ref.
* www.geos.ed.ac.uk/~gisteac/gis_book_abridged/files/ch27
* Spatial Databases: With Application to GIS, Philippe Rigaux
겁나 오래걸리네 이거,,,?
어쩌지
'Study > SDBMS' 카테고리의 다른 글
| SDBMS ⑥ The KD Tree (0) | 2021.04.15 |
|---|---|
| SDBMS ⑤ The Z-Ordering Tree (0) | 2021.04.08 |
| SDBMS ④ The Linear Quadtree (0) | 2021.04.02 |
| SDBMS ② ER Diagram and Relational Schema (0) | 2021.03.15 |
| SDBMS ① Spatial Data Model and Topological Relationship (0) | 2021.03.15 |




댓글